Research
This page provides a broad overview of the topics I've worked on in the past, and is only updated sporadically. Refer to DBLP or Google Scholar for my latest papers.

Safe and secure foundation models
Foundation models—and especially large language models—are being used to construct social companions, personal assistants, and autonomous agents. These applications require a high degree of trust, but deployed applications have proven to be vulnerable to manipulation and misuse in the past: a malicious website author can turn Bing Chat into a phishing agent, and appending a seemingly-random string to your ChatGPT queries can cause it to provide bomb-making tips. I work on evaluating the vulnerability of models to these problems, and improving them so that we can reap the benefits of foundation models even in challenging applications.
S. Toyer, O. Watkins, E.A. Mendes, J. Svegliato, L. Bailey, T. Wang, I. Ong, K. Elmaaroufi, P. Abbeel, T. Darrell, A. Ritter, S. Russell “Tensor Trust: Interpretable Prompt Injection Attacks from an Online Game”. ICLR 2024 (spotlight). [web] [code] [data]
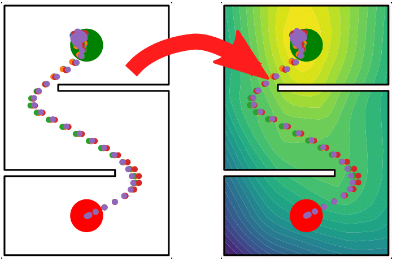
Value learning
Algorithms typically assume access to a loss, goal, reward function, or other objective that adequately captures what a system designer wants the algorithm to do. This is a poor fit for settings where the real objective is difficult to write down by hand (e.g. synthesising aesthetically pleasing images or music), or where the algorithm has enough flexibility to realise simple, hand-specified goals in surprising and undesirable ways. Value learning is the task of automatically discovering what objectives a system ought to pursue, typically by having an algorithm query and interact with people. I view this as a stepping stone to better aligning the behaviour of algorithms with the long-term interests of society, which are by nature fluid and difficult to formalise. In the past, I've pursued this problem by looking at how Inverse Reinforcement Learning (IRL), which infers reward functions from demonstrations of desirable behaviour, can be made more reliable in practice.
X. Chen,* S. Toyer,* C. Wild,* S. Emmons, I. Fischer, K.H. Lee, N. Alex, S.H. Wang, P. Luo, S. Russell, P. Abbeel, R. Shah. “An Empirical Investigation of Representation Learning for Imitation”. NeurIPS 2021 (Datasets & Benchmarks Track). [code]
S Toyer, R. Shah, A. Critch, S. Russell. “The MAGICAL Benchmark for Robust Imitation”. NeurIPS 2020 (poster). [code]
XB Peng, A Kanazawa, S Toyer, P Abbeel, S Levine. “Variational Discriminator Bottleneck: Improving Imitation Learning, Inverse RL, and GANs by Constraining Information Flow”. ICLR 2019 (poster). [IRL code]
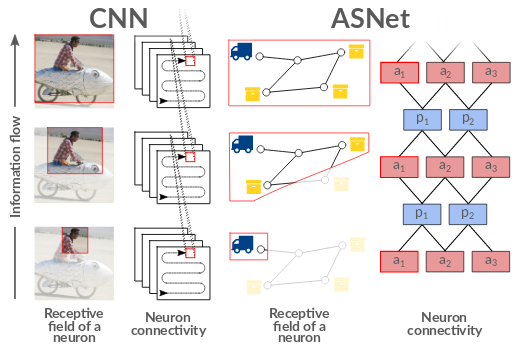
Generalised policies for probabilistic planning
A generalised policy for a family of planning problems is a function which can suggest an appropriate action to take for any state of any problem from that family. For instance, if one wants to solve a series of slightly different truck routing problems (e.g. with different numbers of trucks or different road networks), then it might be possible to obtain a single generalised policy which solves all possible truck routing problems, rather than obtaining a separate policy for each problem. As an undergraduate, I explored how deep learning could be used to represent generalised policies for factored MDPs and classical planning problems.
S Toyer, FW Trevizan, S Thiébaux, L Xie. “ASNets: Deep Learning for Generalised Planning”. JAIR, 2019. [code]
W Shen, FW Trevizan, S Toyer, S Thiébaux, L Xie. “Guiding Search with Generalized Policies for Probabilistic Planning”. SOCS 2019.
S Toyer, FW Trevizan, S Thiébaux, L Xie. “Action Schema Networks: Generalised Policies with Deep Learning”. AAAI 2018. [code]
S Toyer. “Generalized Policies for Probabilistic Planning with Deep Learning”. Honours thesis, ANU 2017. [code]
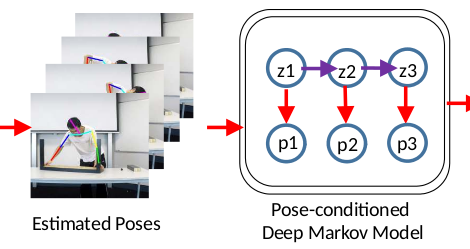
Pose forecasting
Pose forecasting is the task of predicting a person's future motion from an observed sequence of motions. It has potential applications in collaborative robotics, as it can be helpful for a robot to anticipate a person's movement in order to coordinate with them or avoid colliding with them. In a DICTA paper, we proposed a novel pose forecasting method which used recurrent variational autoencoders to model a distribution over future poses. In contrast, previous methods could predict only a single trajectory, and thus did not adequately account for the uncertainty inherent to predicting human motion. Our DICTA paper also introduces Ikea Furniture Assembly—a new dataset for pose forecasting, action anticipation, and related tasks.
S Toyer, A Cherian, T Han, S Gould. “Human Pose Forecasting via Deep Markov Models”. DICTA 2017. [baseline code] [DMM code] [Ikea FA dataset]
Links:
Coverage data on the semantic web
Geoscientists rely on data gathered from a wide range of satellites operated by many different agencies and countries. Satellite data providers often present their information in mutually incompatible formats, which makes it challenging to combine data from different sources. I spent some time working with a student team on interoperable methods for publishing spatial-temporal coverage data using semantic web technology, which led to a Note (W3C equivalent of a technical report) published by the W3C/OGC Spatial Data on the Web Working Group, as well as some software demonstrating how to publish coverage data on the web.
D Brizhinev, S Toyer, K Taylor. “Publishing and Using Earth Observation Data with the RDF Data Cube and the Discrete Global Grid System”. W3C Working Group Note 2017. [AGU'16 abstract] [code]